
Table of Contents
This post explores architectural workflow patterns designed to regulate context size within agentic applications.
If 2025 was the year of the agent, 2026 is the year of context management.
As applications scale and data volumes surge, the risk of "context bloat" increases with every model call. These oversized payloads don't just drive up costs and latency; they actively degrade the LLM’s ability to make accurate, reliable decisions.
Travel Planning Use Case
We will base our context management discussion on a Travel Planning use case
A typical agentic MVP involves creating a travel planning agent and providing it with a flight search tool. The user requests a flight search based on input criteria, the agent calls the tool, formats the results and returns them to the user.
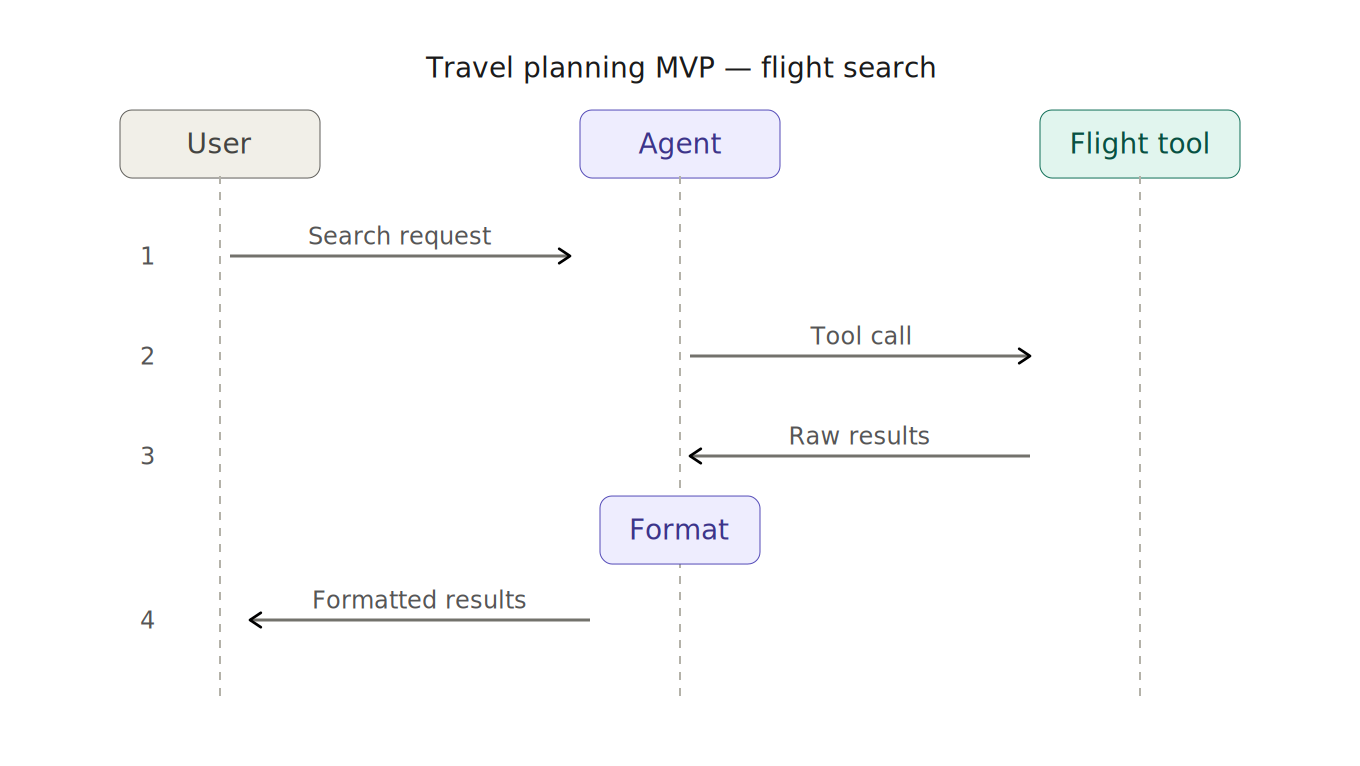
Initial Thoughts On This Design
This agent, tool setup is easy to implement and get quick results, but it’s also where the context management problems start:
- Returned Results: unless we implement paging, or results cap, we don’t know the size and count of results returned from the Flight Tool.
- User Requests: the user can make multiple requests which combined with unknow return results size, means the Agent context is bloated.
- Data Use: we are returning large amounts of data into the agent context which is not being used by the agent/LLM.
- Scalability: we are compounding this problem when we add new features like hotels, car rentals etc.
Tool Calling in AI Frameworks
LLM frameworks such as Microsoft Agent Framework, LangChain or Mastra handle the tool-call loop internally.
The LLM parses the user input, generates the tool-call request, and includes it in its response. The framework then executes the tool and feeds the results back into the second LLM call. Finally, the LLM’s response is returned to the user or called.
While convenient, this approach sacrifices flexibility. Gaining access to the underlying data and internal tool calls is the essential first step in managing context bloat.
A Better Design
To solve the issue of context bloat, we can decouple the agent from the physical tool-calling process. In this design, the LLM still responds with a tool-call signature, but instead of allowing the framework to execute it automatically, we handle the call manually.
The new sequence:
- The user submits their request.
- The LLM generates the tool-call signature and returns it to the application.
- The application intercepts this signature and calls the Flight Tool.
- We generate a unique ID for the raw results and persist them to external storage.
- We return a summarized, fixed size message, to the LLM.
- The LLM provides a final response the the User.
- The UI renders the response to the user and downloads the full results.
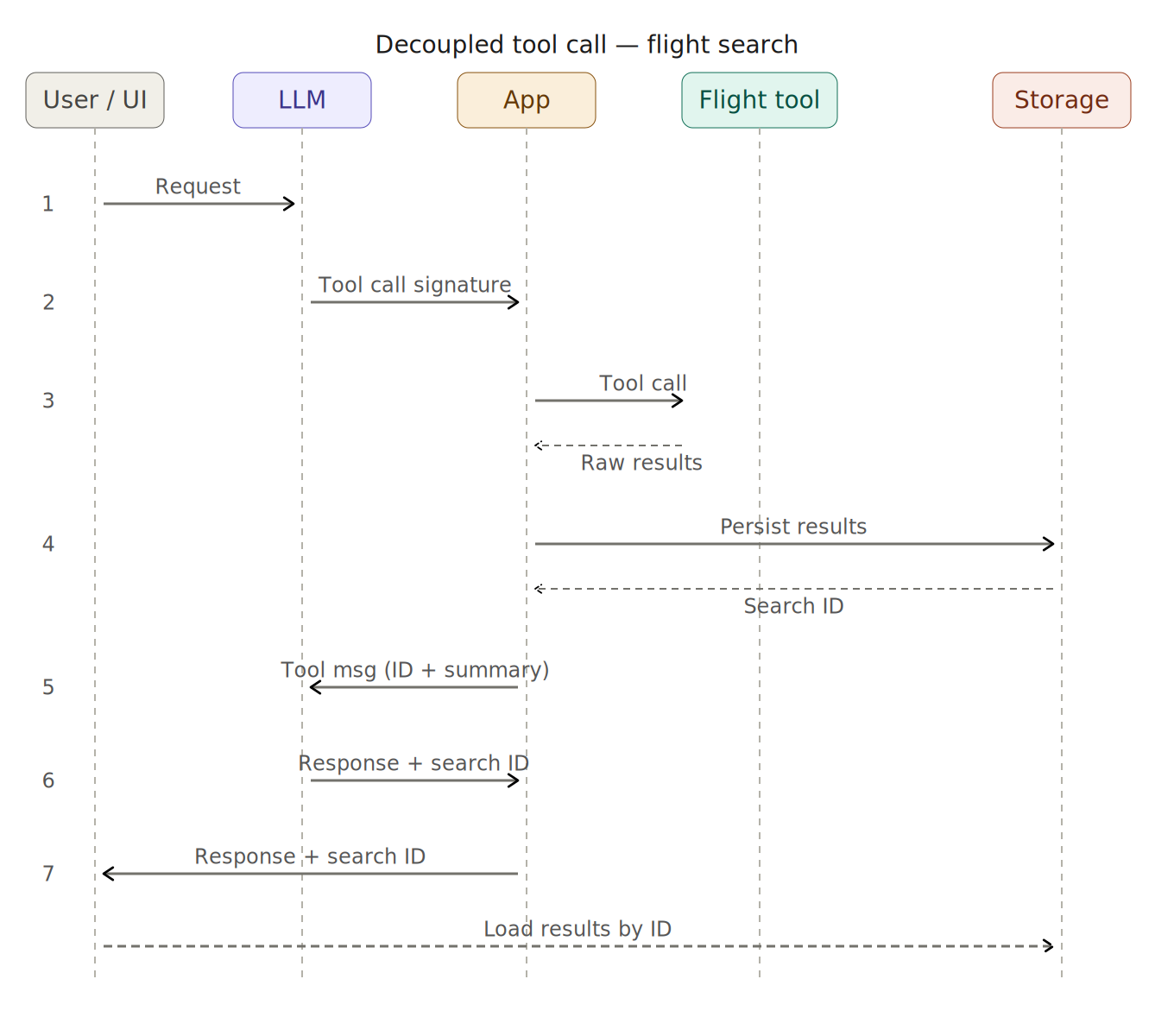
Deterministic Results
With this architecture, you know exactly what is being fed back into the LLM. There are no surprises regarding context size, token usage, or latency so predictability is guaranteed.
Why Determinism Matters
When raw tool responses flow directly into the context window, your token budget becomes a function of external data you do not control. A flight search returning 5 results versus one returning 200 results will produce widely different context sizes, costs, and latencies.
More importantly, a bloated context degrades the LLM’s ability to make accurate decisions.
{
"flights": [
{
"flightNumber": "FR1234",
"origin": "DUB",
"destination": "CDG",
"departureTime": "2026-04-01T06:45:00",
"arrivalTime": "2026-04-01T09:55:00",
"duration": "2h 10m",
"stops": 0,
"aircraft": "Boeing 737-800",
"availableSeats": 47,
"cabinClass": "Economy",
"price": 89.99,
"currency": "EUR",
"baggage": "1 carry-on included",
"operator": "Ryanair",
"bookingClass": "V",
"fareConditions": "Non-refundable, no changes"
}
// ... 199 more
]
}
You return the bare minimum required for the LLM to reason:
Dublin to Paris: 20 flight options found.
Cheapest: €89 (06:45 departure).
Fastest: 2h 10m.
ID: EF2XJ49Code to intercept and make the manual tool call:
var result = await function.InvokeAsync(
new AIFunctionArguments(functionCallContent.Value.Arguments),
cancellationToken);
// Persist raw results to storage, get back a reference ID
var searchId = await _searchStore.PersistAsync(result);
// Build a controlled summary — this is all the LLM sees
var summary = FlightSearchSummary.From(result, searchId);
toolResults.Add(new FunctionResultContent(
functionCallContent.Value.CallId,
summary.ToString()));By returning only the summary and search ID, these references become part of the conversation history. The LLM can then reference them across subsequent turns without extra effort. For example, if a user says, "Book the second option," the LLM uses the ID already in context to reason against the stored data. The full result set remains in storage for the life of the session, never cluttering the context window again.
Until Next Time
Context management is a silent issue—it creeps in one tool result at a time as your application grows. By decoupling tool calls and owning what enters the LLM's window, you move from hoping your context stays manageable to ensuring it does.
In our next post, we’ll scale this pattern to multi-agent systems. We’ll look at how specialist agents for hotels, cars, and restaurants can use "summarize-and-store" to avoid polluting a shared conversation. Finally, we’ll see how an Orchestrator coordinates these agents while keeping its own context footprint lean.




{kind=link}